I’m sure if I had a nickel for each time a software project was impacted by introducing production volume data into the testing life cycle either too late, or worse even – not at all, I’d be a rich man and wouldn’t be writing this blog entry. When you think about it, it’s really no wonder that we find ourselves in this situation. Developers new to the craft have no experience to draw on dealing with millions of rows of data. Experienced developers and DBAs often pass on war stories of hand crafted scripts and the perils of migrating data from production to lower environments, further reinforcing the belief that emulating production volumes of data is work restricted to the gods of IT.
Taking this trend a step further, applications are often exposed for the briefest of periods to data resembling production volume data during the test cycle. Even then, the data reflects yesterday’s production volumes and not next year’s volumes. Furthermore, testing of certain other functions is restricted because these functions either deal with new data where there is, as of yet, no production data or they deal with other external systems that have test data that’s out-of-sync with the data of the system under test.
Does preparing production volume data really need to be this difficult? No!
This entry deals with the use of Red Gate Software’s SQL Data Generator product to generate a large volume of data for a simple test database. Why would one choose to use a product such as SQL Data Generator to generate test data instead of using alternate methods such as copying production data or creating custom data generation scripts? There are several reasons:
- Obfuscation of personally identifiable information (PII) from production data is a painful process. See point #2
- Syncing data between systems is a very painful process. More so if the obfuscated data from step #1 is used across systems
- By using production data, you’re only testing for current capacity, not for planned capacity 3, 6, or 12 months from now
- If the application or elements of the application are new, you may not have any relevant data to test with at all
- Writing custom data generation scripts is either (i) a one-off process that yields brittle scripts tied to a particular version of the schema; (ii) an exercise in re-inventing the wheel since commercial tools have already been built to do this.
Sample Data Model
Our data model is simple enough to be readily understandable while still presenting a couple of challenges that will illustrate some of the features of the SQL Data Generator tool. The data model serves as the backend for an online travelling site that collects and manages community-driven travel recommendations. Think about the book 1000 Places to See Before You Die as a Web2.0’ish site. Users can enter new tours / places, bundle similar or geographically close tours into tour packages, and provide user-specific tags for both tours and packages.

There are several characteristics of this data model that are somewhat challenging and provide an opportunity to illustrate some of SQL Data Generator’s more advanced options. These features are:
- Both the package and tour ids are unique identifiers (GUIDs). They are referenced by the ContributorId in the Tags table but there is no foreign key constraint. That is, a ContributionId is a GUID which may match up with either a tour id or a package id.
- The sequence numbers within the TourPackages table represent the visual display order of the tours within the package. Therefore the sequence numbers cannot be random and must cycle through each of the tours in a package without repeating within that package.
- The data generated for the model has to follow statistical distributions representative of the production environment, such as:
- There should be 5 times as many tours as users with the number of tours per user following a normal statistical distribution between 1 and 10 tours.
- The total number of packages should be 40% of the total number of tours. Tours distribution amongst the packages should be random
- Total tags should be 60% of total tours. The vast majority of these tags (almost 10-to-1) should be attributed to tours. The remained are attributed to tour packages.
Basic SQL Data Generator Capabilities
Creating a project with SQL Data Generator is as easy as selecting the database you wish to generate data into.

Once the project is created, SQL generator will infer information about the data based upon the column types and other characteristics. You can then review sample data and tweak the configuration options to meet your needs.

Specifying valid values for the Tour table’s longitude column. Changes to the generator settings are immediately reflected in the sample data set, providing the opportunity to validate the impacts of the changes.
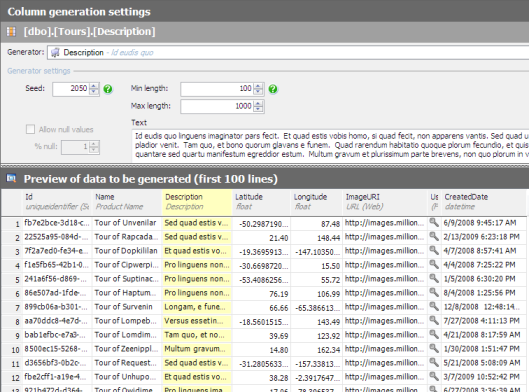
Intermediate SQL Data Generator Capabilities
Specifying the mechanism to determine how many rows to generate is made easy within SQL Data Generator. This enables the data to be generated in proportion to production ratios, as stipulated in our requirements.

These same capabilities allow us to address the requirements around TourPackage sequence numbers by letting SQL Data Generator handle the generation of combinations within the TourId / Package Id composite key space.
Lastly, SQL Data Generator can use alternate generator sources, such as the output of SQL statements or direct input from a CSV file. In our case, this allows us to specify a SQL statement to pull the appropriate Ids from the Tour and Package tables for the reference Id values in the Tag table even though no explicit foreign key relationship is present.
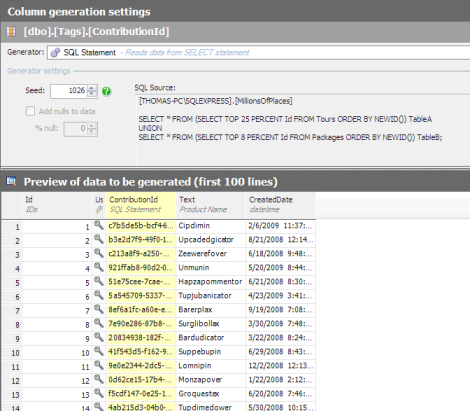
Advanced SQL Data Generator Capabilities
Custom generators can be created for use with the SQL Data Generator. This enables domain specific data to be generated and the generators to be re-used across multiple projects. Custom generators are written in .NET code by implementing one of RedGate’s generator interfaces. Although this is not particularly difficult, it is beyond the scope of this post.
Generating Data
Once the generation options are specified in accordance with the requirements, the only thing left to do is generate the data. The data population action plan gives you an idea of what data will be going where.

Running the generation script against a local SQL Server Express installation on a small (one processor, 2 GB RAM) VMWare machine, SQL Data Generator was able to generate 420,000 records across 5 tables in less than 1 minute, yielding a total database size of about 400 MB.

Other SQL Data Generator Capabilities
At this point in this blog entry, I’m hoping you’re at least starting to believe that data generation can be fast and easy. There are several other benefits to data generation with SQL Data Generator that weren’t covered here:
- Project seamlessly incorporates changes to the underlying schema
- The SQL Data Generator project file (extension “.sqlgen”) can be version controlled in conjunction with the scripts to create the database, providing the ability to create and fully populate current and historic versions of the database to align with application code changes.
- If the seed numbers are not changed, the data generated is exactly the same across generations. If you need new / different data, change the seed number.
Related Links
- SQL Data Generator Home Page – http://www.red-gate.com/products/sql_data_generator/index.htm
- SQL Data Generator Documentation – http://www.red-gate.com/supportcenter/Content.aspx?p=SQL%20Data%20Generator&c=SQL_Data_Generator/help/1.2/SDG_Getting_Started.htm&toc=SQL_Data_Generator/help/1.2/toc.htm
- SQL Data Generators Community Site – http://www.codeplex.com/SDGGenerators
- SQL Data Generator Project File and SQL Scripts for this Article – http://s3.beckshome.com/20090704-Generating-Data-Source-Files.zip